
XENON with NVIDIA® is dedicated to empowering and collaborating with professors and researchers at all universities and educational institutions. We aim to inspire cutting-edge technological innovation and to find new ways of enhancing faculty research as well as the teaching and learning experience.
If you are affiliated with an educational institution in Australia or NZ then you are eligible for a significant discount on NVIDIA® Volta™ GPUs. Contact XENON today about this program at info@xenon.com.au or 1300 030 888.
The Most Advanced Data Center GPU Ever Built
NVIDIA® Tesla® V100 is the world’s most advanced data center GPU ever built to accelerate AI, HPC, and graphics. Powered by NVIDIA® Volta™, the latest GPU architecture, Tesla V100 offers the performance of up to 100 CPUs in a single GPU—enabling data scientists, researchers, and engineers to tackle challenges that were once thought impossible.

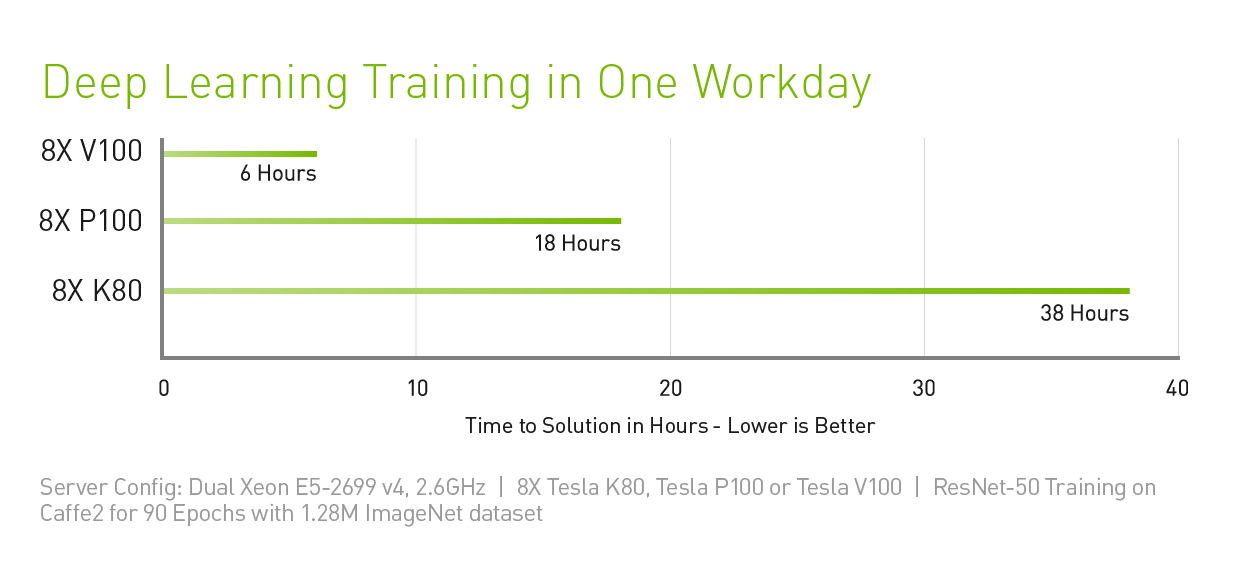
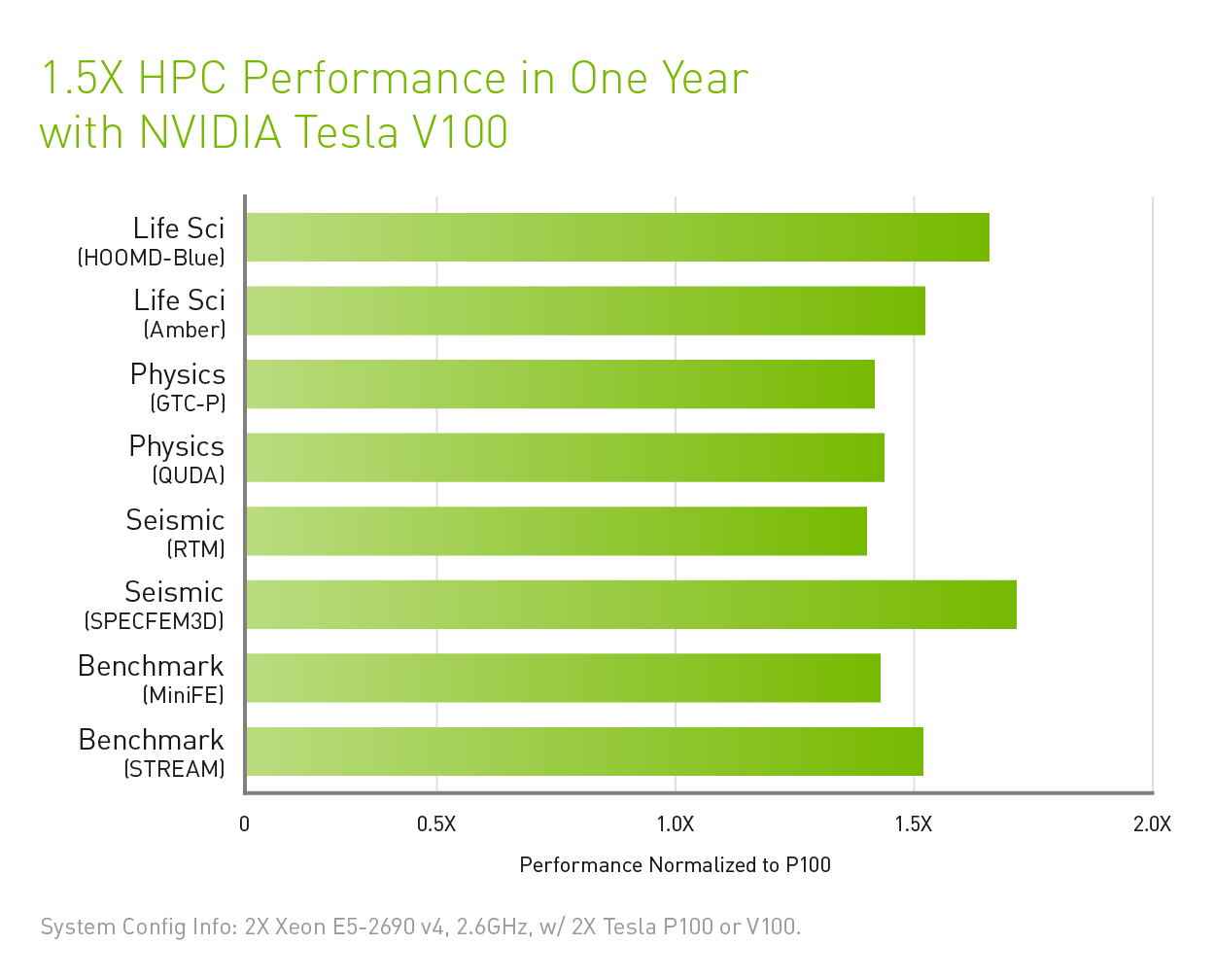
PERFORMANCE SPECIFICATION FOR NVIDIA® Tesla® V100 is:
| Tesla V100 PCle | Tesla V100 SXM2 | |
|---|---|---|
 |
 |
|
| GPU Architecture | NVIDIA® Volta™ | |
| NVIDIA Tensor Cores | 640 | |
| NVIDIA CUDA® Cores | 5,120 | |
| Double-Precision Performance | 7 TFLOPS | 7.8 TFLOPS |
| Single-Precision Performance | 14 TFLOPS | 15.7 TFLOPS |
| Tensor Performance | 112 TFLOPS | 125 TFLOPS |
| GPU Memory | 16 GB HBM2 | |
| Memory Bandwidth | 900 GB/sec | |
| ECC | Yes | |
| Interconnect Bandwidth | 32 GB/sec | 300 GB/sec |
| System Interface | PCIe Gen3 | NVIDIA NVLink |
| Form Factor | PCIe Full Height/Length | SXM2 |
| Max Power Consumption | 250 W | 300 W |
| Thermal Solution | Passive | |
| Compute APIs | CUDA, DirectCompute, OpenCL™, OpenACC | |
GROUNDBREAKING INNOVATIONS

Volta Architecture
By pairing CUDA Cores and Tensor Cores within a unified architecture, a single server with Tesla V100 GPUs can replace hundreds of commodity CPU servers for traditional HPC and Deep Learning.

Tensor Core
Equipped with 640 Tensor Cores, Tesla V100 delivers 125 TeraFLOPS of deep learning performance. That’s 12X Tensor FLOPS for DL Training, and 6X Tensor FLOPS for DL Inference when compared to NVIDIA Pascal™ GPUs.
Next Generation NVLink
NVIDIA NVLink in Tesla V100 delivers 2X higher throughput compared to the previous generation. Up to eight Tesla V100 accelerators can be interconnected at up to 300 GB/s to unleash the highest application performance possible on a single server.
Maximum Efficiency Mode
The new maximum efficiency mode allows data centers to achieve up to 40% higher compute capacity per rack within the existing power budget. In this mode, Tesla V100 runs at peak processing efficiency, providing up to 80% of the performance at half the power consumption.

HBM2
With a combination of improved raw bandwidth of 900 GB/s and higher DRAM utilization efficiency at 95%, Tesla V100 delivers 1.5X higher memory bandwidth over Pascal GPUs as measured on STREAM.
Programmability
Tesla V100 is architected from the ground up to simplify programmability. Its new independent thread scheduling enables finer-grain synchronization and improves GPU utilization by sharing resources among small jobs.


Get a Quote Talk to a Solutions Architect


