
Tesla V100: The AI Computing and HPC Powerhouse
The NVIDIA® Tesla® V100 accelerator is the world’s highest performing parallel processor, designed to power the most computationally intensive HPC, ArtificiaI Intelligence, and graphics workloads.
The GV100 GPU includes 21.1 billion transistors with a die size of 815 mm2. It is fabricated on a new TSMC 12 nm FFN high performance manufacturing process customized for NVIDIA. GV100 delivers considerably more compute performance, and adds many new features compared to its predecessor, the Pascal GP100 GPU and its architecture family. Further simplifying GPU programming and application porting, GV100 also improves GPU resource utilization. GV100 is an extremely power-efficient processor, delivering exceptional performance per watt. Figure 2 shows Tesla V100 performance for deep learning training and inference using the ResNet-50 deep neural network.
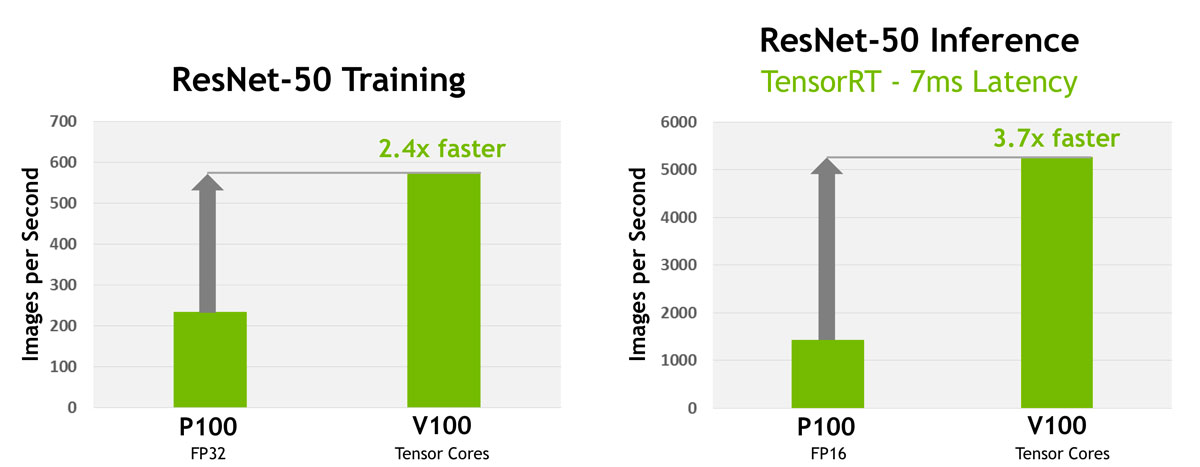 Figure 1: Left: Tesla V100 trains the ResNet-50 deep neural network 2.4x faster than Tesla P100. Right: Given a target latency per image of 7ms, Tesla V100 is able to perform inference using the ResNet-50 deep neural network 3.7x faster than Tesla P100. (Measured on pre-production Tesla V100.)
Figure 1: Left: Tesla V100 trains the ResNet-50 deep neural network 2.4x faster than Tesla P100. Right: Given a target latency per image of 7ms, Tesla V100 is able to perform inference using the ResNet-50 deep neural network 3.7x faster than Tesla P100. (Measured on pre-production Tesla V100.)COMPARISONS
This table 1 compares NVIDIA® Tesla® accelerators over the past 5 years.
| Tesla Product | Tesla K40 | Tesla M40 | Tesla P100 | Tesla V100 |
|---|---|---|---|---|
 |
 |
 |
 |
|
| GPU | GK180 (Kepler) | GM200 (Maxwell) | GP100 (Pascal) | GV100 (Volta) |
| SMs | 15 | 24 | 56 | 80 |
| TPCs | 15 | 24 | 28 | 40 |
| FP32 Cores/SM | 192 | 128 | 64 | 64 |
| FP32 Cores/GPU | 2880 | 3072 | 3584 | 5120 |
| FP64 Cores/SM | 64 | 4 | 32 | 32 |
| FP64 Cores/GPU | 960 | 96 | 1792 | 2560 |
| Tensor Cores/SM | NA | NA | NA | 8 |
| Tensor Cores/GPU | NA | NA | NA | 640 |
| GPU Boost Clock | 810/875 MHz | 1114 MHz | 1480 MHz | 1455 MHz |
| Peak FP32 TFLOP/s* | 5.04 | 6.8 | 10.6 | 15 |
| Peak FP64 TFLOP/s* | 1.68 | 2.1 | 5.3 | 7.5 |
| Peak Tensor Core TFLOP/s* | NA | NA | NA | 120 |
| Texture Units | 240 | 192 | 224 | 320 |
| Memory Interface | 384-bit GDDR5 | 384-bit GDDR5 | 4096-bit HBM2 | 4096-bit HBM2 |
| Memory Size | Up to 12 GB | Up to 24 GB | 16 GB | 16 GB |
| L2 Cache Size | 1536 KB | 3072 KB | 4096 KB | 6144 KB |
| Shared Memory Size/SM | 16 KB/32 KB/48 KB | 96 KB | 64 KB | Configurable up to 96 KB |
| Register File Size/SM | 256 KB | 256 KB | 256 KB | 256KB |
| Register File Size/GPU | 3840 KB | 6144 KB | 14336 KB | 20480 KB |
| TDP | 235 Watts | 250 Watts | 300 Watts | 300 Watts |
| Transistors | 7.1 billion | 8 billion | 15.3 billion | 21.1 billion |
| GPU Die Size | 551 mm² | 601 mm² | 610 mm² | 815 mm² |
| Manufacturing Process | 28 nm | 28 nm | 16 nm FinFET+ | 12 nm FFN |
(* Peak TFLOP/s rates are based on GPU Boost clock.)
Key Features
Key compute features of Tesla V100 include the following:
-
New Streaming Multiprocessor (SM) Architecture Optimized for Deep Learning Volta features a major new redesign of the SM processor architecture that is at the center of the GPU. The new Volta SM is 50% more energy efficient than the previous generation Pascal design, enabling major boosts in FP32 and FP64 performance in the same power envelope. New Tensor Cores designed specifically for deep learning deliver up to 12x higher peak TFLOPs for training. With independent, parallel integer and floating point datapaths, the Volta SM is also much more efficient on workloads with a mix of computation and addressing calculations. Volta’s new independent thread scheduling capability enables finer-grain synchronization and cooperation between parallel threads. Finally, a new combined L1 Data Cache and Shared Memory subsystem significantly improves performance while also simplifying programming.
- HBM2 Memory: Faster, Higher Efficiency Volta’s highly tuned 16GB HBM2 memory subsystem delivers 900 GB/sec peak memory bandwidth. The combination of both a new generation HBM2 memory from Samsung, and a new generation memory controller in Volta, provides 1.5x delivered memory bandwidth versus Pascal GP100 and greater than 95% memory bandwidth efficiency running many workloads.
- Volta Multi-Process Service Volta Multi-Process Service (MPS) is a new feature of the Volta GV100 architecture providing hardware acceleration of critical components of the CUDA MPS server, enabling improved performance, isolation, and better quality of service (QoS) for multiple compute applications sharing the GPU. Volta MPS also triples the maximum number of MPS clients from 16 on Pascal to 48 on Volta.
-
Second-Generation NVLink™ The second generation of NVIDIA’s NVLink high-speed interconnect delivers higher bandwidth, more links, and improved scalability for multi-GPU and multi-GPU/CPU system configurations. GV100 supports up to 6 NVLink links at 25 GB/s for a total of 300 GB/s. NVLink now supports CPU mastering and cache coherence capabilities with IBM Power 9 CPU-based servers. The new NVIDIA DGX-1 with V100 AI supercomputer uses NVLink to deliver greater scalability for ultra-fast deep learning training.
- Enhanced Unified Memory and Address Translation Services GV100 Unified Memory technology in Volta GV100 includes new access counters to allow more accurate migration of memory pages to the processor that accesses the pages most frequently, improving efficiency for accessing memory ranges shared between processors. On IBM Power platforms, new Address Translation Services (ATS) support allows the GPU to access the CPU’s page tables directly.
- Cooperative Groups and New Cooperative Launch APIs Cooperative Groups is a new programming model introduced in CUDA 9 for organizing groups of communicating threads. Cooperative Groups allows developers to express the granularity at which threads are communicating, helping them to express richer, more efficient parallel decompositions. Basic Cooperative Groups functionality is supported on all NVIDIA GPUs since Kepler. Pascal and Volta include support for new Cooperative Launch APIs that support synchronization amongst CUDA thread blocks. Volta adds support for new synchronization patterns.
-
Volta Optimized Software New versions of deep learning frameworks such as Caffe2, MXNet, CNTK, TensorFlow, and others harness the performance of Volta to deliver dramatically faster training times and higher multi-node training performance. Volta-optimized versions of GPU accelerated libraries such as cuDNN, cuBLAS, and TensorRT leverage the new features of the Volta GV100 architecture to deliver higher performance for both deep learning and High Performance Computing (HPC) applications. The NVIDIA CUDA Toolkit version 9.0 includes new APIs and support for Volta features to provide even easier programmability.
- Maximum Performance and Maximum Efficiency Modes In Maximum Performance mode, the Tesla V100 accelerator will operate unconstrained up to its TDP (Thermal Design Power) level of 300W to accelerate applications that require the fastest computational speed and highest data throughput. Maximum Efficiency Mode allows data center managers to tune power usage of their Tesla V100 accelerators to operate with optimal performance per watt. A not-to-exceed power cap can be set across all GPUs in a rack, reducing power consumption dramatically, while still obtaining excellent rack performance.
 Tensor Core
Tensor Core NVIDIA® NVLink
NVIDIA® NVLink Volta-Optimized Software
Volta-Optimized SoftwareFor more information, please contact XENON or call to speak to a solutions architect, 1300 030 888.


